Human video generation remains challenging, as it requires jointly modeling appearance, motion, and camera viewpoint under limited multi-view data. Existing methods often treat these factors separately, leading to limited controllability or reduced visual quality.
We revisit this problem from an image-first perspective, where high-quality appearance is learned via image generation and used as a prior for video synthesis, decoupling appearance from temporal consistency.
We propose a pose- and viewpoint-controllable pipeline that combines a pretrained image backbone with SMPL-X motion guidance, together with a training-free temporal refinement stage based on a pretrained video diffusion model.
Our method produces high-quality, temporally consistent videos under diverse poses and viewpoints. We also release a canonical human dataset and an auxiliary model for compositional human image synthesis.
Our synthesis results are smooth and temporally consistent, even under large viewpoint changes.
Our method is capable of synthesizing humans with in-the-wild appearance and motion.

Disentangled assets from our canonical training setup: face, upper / lower clothing, and shoes.
Additional rows: face, full outfit, and shoes .
We additionally train a compositional human image synthesis model on our canonical human dataset.

Our image-first pipeline splits the problem into two steps: (1) per-frame pose- and view-conditioned synthesis, then (2) training-free temporal alignment. Given canonical front/back appearance, an SMPL‑X motion sequence, and target camera views, we generate consistent frames and refine them into a coherent video.
A fine-tuned pretrained image backbone (e.g., Flux/Kontext with LoRA) renders each frame from SMPL‑X normal cues, keeping identity and clothing aligned across poses and viewpoints.
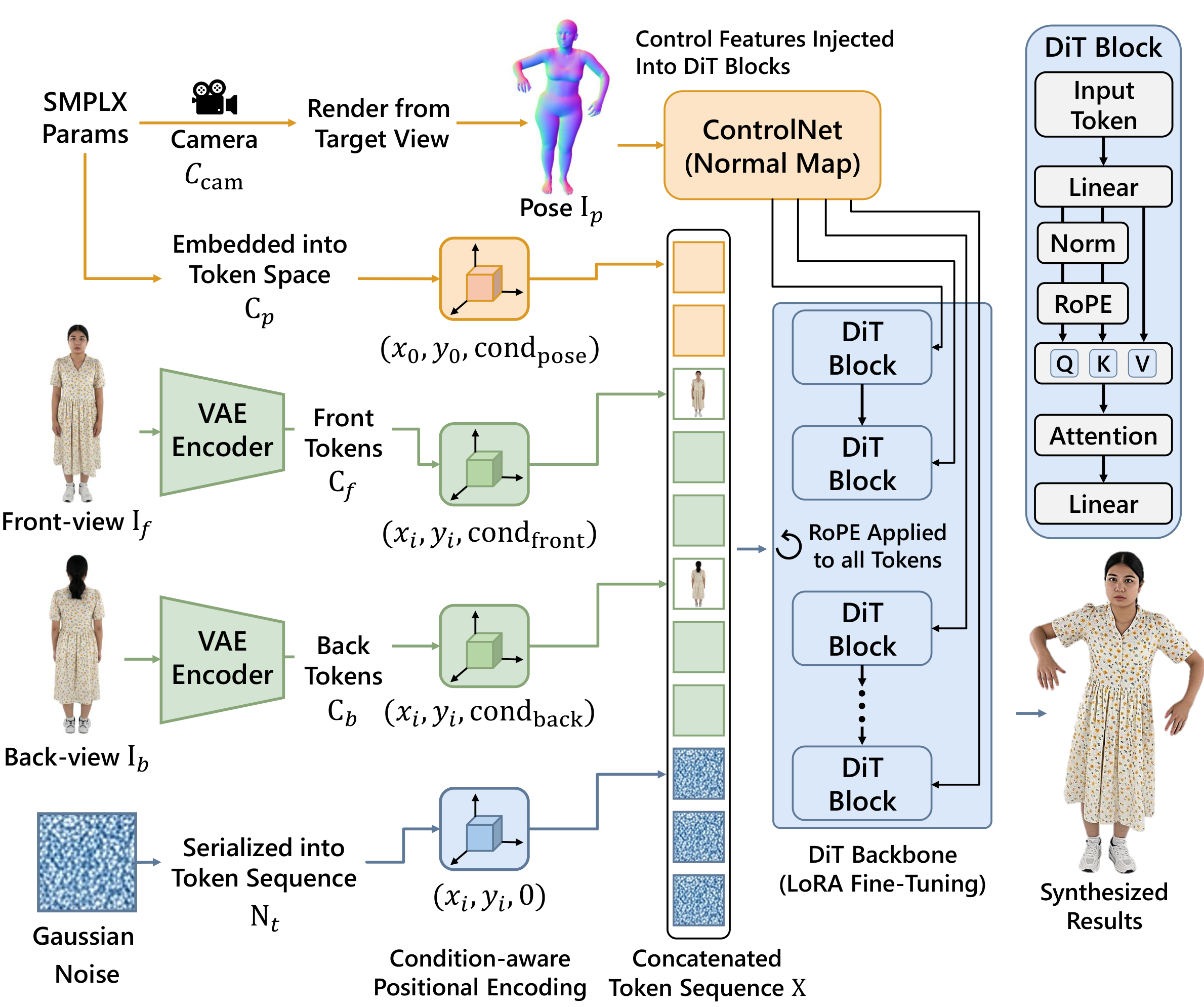
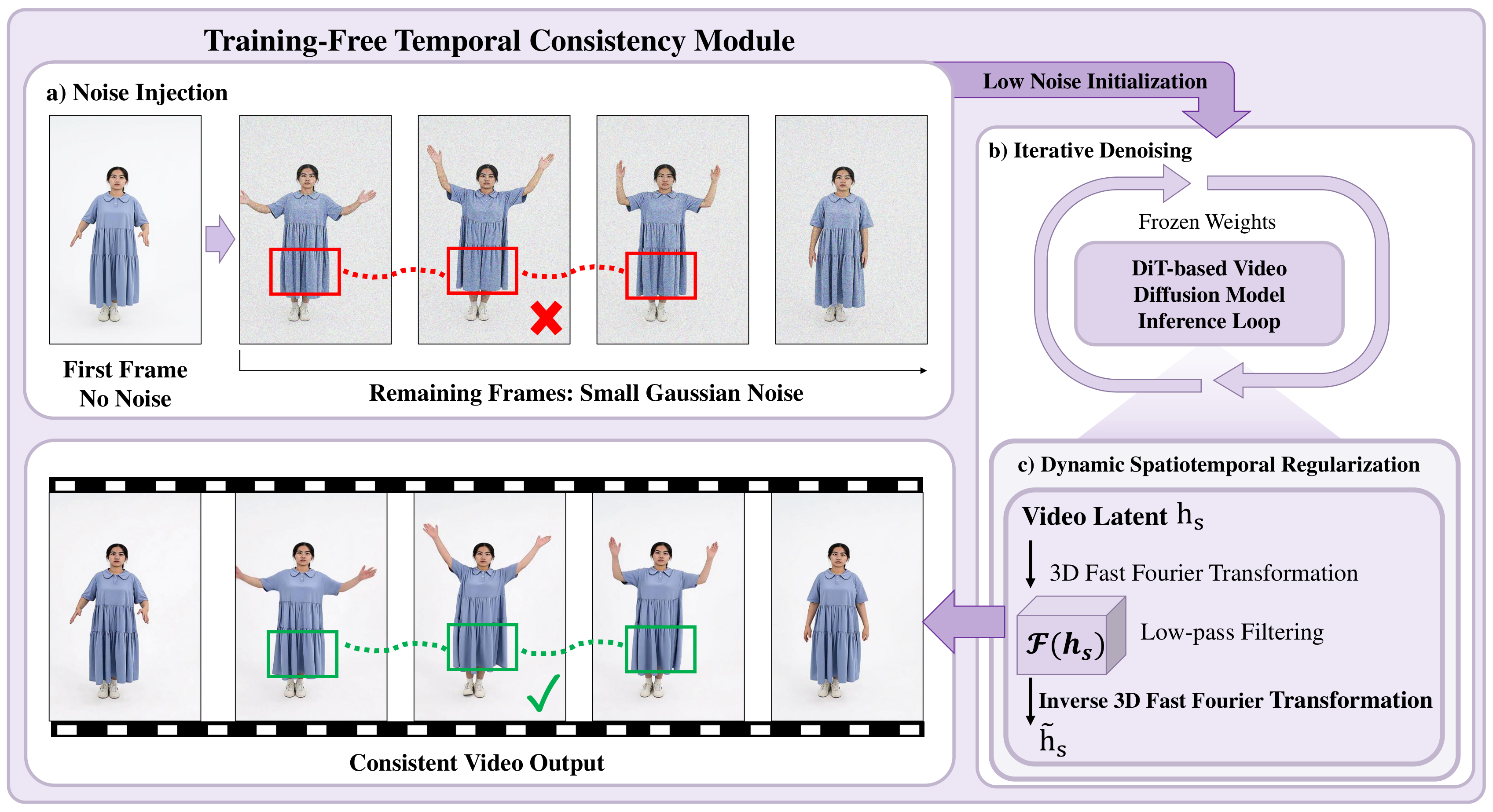
A pretrained video diffusion model refines the frame sequence at inference only: latent blending and feature propagation reduce flicker, stabilize motion, and preserve identity. There is no extra temporal training.
Longer walk-through with additional results.
If you use this work, you can cite it with the BibTeX entry below.
@article{sun2025rethinking,
title={ReImagine: Rethinking Controllable High-Quality Human Video Generation via Image-First Synthesis},
author={Sun, Zhengwentai and Zheng, Keru and Li, Chenghong and Liao, Hongjie and Yang, Xihe and Li, Heyuan and Zhi, Yihao and Ning, Shuliang and Cui, Shuguang and Han, Xiaoguang},
journal={arXiv preprint arXiv:2604.19720},
year={2026},
url={https://arxiv.org/abs/2604.19720v1}
}


